elly - PRs you can act on
elly shows you all of the pull requests you can take action on, by periodically pulling data from Github.
You should deal with the PRs in order, they're ranked by actionability.
For example, if a PR gets approved, elly shows the PR in the top - just merge it.
If there's a new comment, elly bumps that PR up.
If you just responded to someone's comment, but kept the comment thread open instead of resolving it, elly knows you're waiting for a reply and places the PR lower in the list.
This is what it looks like:


Installation instructions
You'll find up to date installation instructions in the project's README.
System design
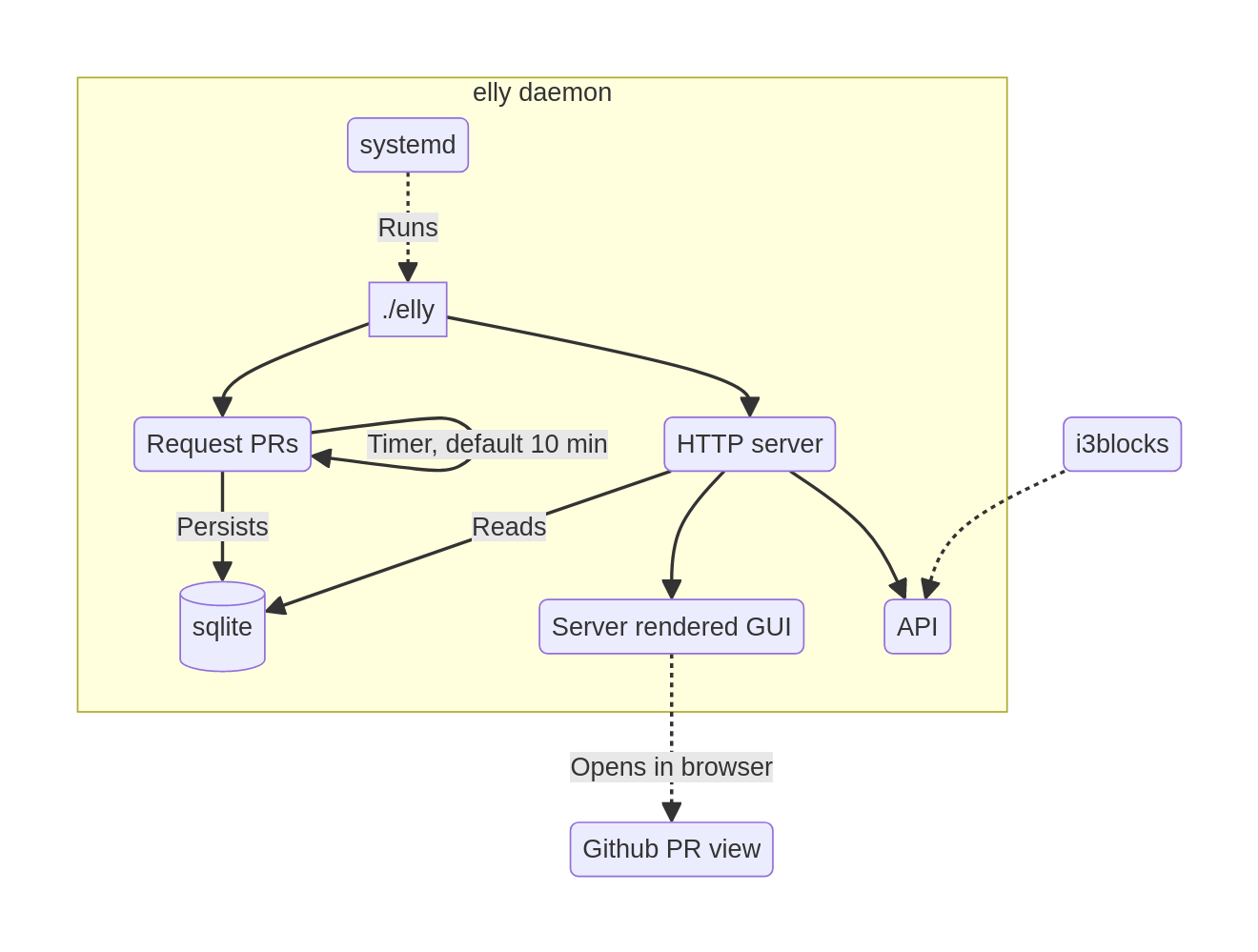
A small retrospective
-
- A single test found 3 bugs
- Inspired by re-reading Dan Luu on testing for the fiftieth time. Finally something that unblocked me, after having read countless "reversing things twice" or "encoding/decoding is commutative" example. Writing longer test method bodies are fine.
- Going from one-off unit tests, to table driven tests, to fuzzying, seems like a path I want to go down.
-
Writing ADRs (architectural decision record) helped even for such a small project (see the
/decisionsfolder)- Feels nice to not having to go back on certain decisions, since they're spelled out and reasoned about. For example: KISS, with a JSON file rather than an SQLite DB, felt better after articulating it in text.
- Went back and edited them a lot. They should probably have the draft or suggestion status for a while.
- The relation between retrospective items and ADRs almost feel 1:1. Using these methods, or something else, that triggers thinking about design before/during/after implementation is gold.
-
- First time querying against it. Using headers for auth, getting proper response codes back, and having the query in plain text is pleasant.
- Github specific:
- Good API explorer, especially with the search box. I guess that the explorer is standard, through some framework.
- Trying to extract enough comments (below pull requests, below repositories, below search results) is weird - should I traverse that paginated sub-sub-sub resource? The "a single query that reaches everywhere" paradigm breaks down a bit, to me.
-
Front end
- Making a footer really sticky
<dialog/>. Amazing that this now exists. No deps/configuration needed, and::backdropis a perfect partner.- Chrome dev tool's flexbox editor. Never noticed this before, it's makes for a very quick feedback cycle.
-
systemd integration
-
Prior art: Gitlab variant (gitlab-mr-bot)
- I made this while at my previous employer who self-hosted Gitlab, where it worked fine.
- Gitlab's API for threads/comments on PRs is much easier to deal with (elly needs to guess if there are unanswered comments, since that schema is paginated in a nested way).
gitlab-mr-botwas used as a one-off script, storing state in SQLite, for others to query.- I'm leaning towards "hiding things behind an API is friendler", especially if one wants to host things remotely. The transparency/hackability of having SQLite is very nice though.